nayeoniee
2022. 9. 4. 01:44
입력 이미지 크기와 상관없이 CNN을 적용할 수 있도록 Spatial Pyramid Pooling 기법을 제안한 논문이다.
1. 배경

R-CNN
이전에 제안된 R-CNN은 convolution layer 이전에 crop이나 warp로 이미지 크기를 고정시킨 후 2000개의 영역에 CNN을 통과시켰다. 따라서 다음과 같은 단점을 가진다.
- 2000개의 region에 각각 CNN을 통과시킨다. → CNN 연산량이 너무 많아 속도가 느려진다.
- 강제 warping → 큰 객체는 줄이고, 작은 객체는 늘려 정보 손실로 인해 성능이 하락할 수 있다.
- CNN, SVM classifier, bounding box regressor를 따로 학습해야한다.
- end-to-end 모델이라고 볼 수 없다.
SPPnet
입력 이미지를 먼저 CNN에 통과시켜 feature map을 뽑은 후, 이미지 크기를 동일하게 맞추지 않고도 FC layer에 넣는 spatial pyramid pooling 방법을 제안했다. 사실 convolution 연산을 할 때는 입력 이미지의 크기를 맞출 필요가 없고, FC layer에서 입력을 고정된 크기로 맞추어야 한다.
FC layer를 통과한 이후 SVM과 bbox regression을 수행하는 것은 동일하다.
2. Architecture

- 입력 이미지를 pre-trained CNN에 통과시켜 feature map을 추출한다.
- selective search로 얻은 2000개의 ROI에 spatial pyramid pooling을 적용해 고정된 크기의 feature map으로 변환한다.
- FC layer를 통과하고 SVM을 활용한 분류, bbox regression을 통한 bbox 좌표 조정을 수행한다.
3. Spatial Pyramid Pooling

- convolution layer를 거친 feature map을 입력으로 받아 미리 정해져 있는 영역으로 나눈다.
위의 예시에서는 4x4, 2x2, 1x1 3가지 영역(피라미드)을 제공하며, 64x64x256 크기의 feature map이 들어왔을 때,
4x4 피라미드 한 칸(bin)의 크기는 16x16 이다. - 각 bin에서 가장 큰 값만 추출하는 max pooling을 수행하고, 결과를 concat한다. (이어붙인다)
입력 이미지의 채널 크기를 $k$, bin의 개수를 $M$이라 하면 SPP 이후 최종 output vector는 $k*M$ 차원이다.
위의 예시에서 k=256, M = 16+4+1 = 21 이므로 256x21 차원의 벡터를 생성한다.
Max Pooling 예시
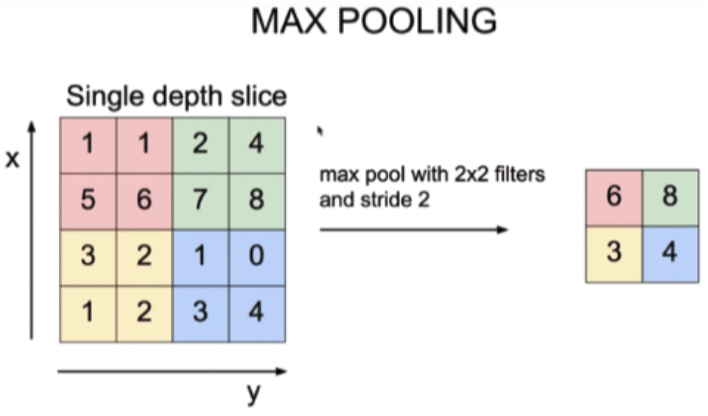
2x2 filter로 pooling을 수행하면 4칸씩 묶어서 max를 뽑지아 같은 크기의 filter로 pooling을 수행해도 입력 이미지의 크기가 다르면 출력 feature map 크기도 다르다.
Spatial Pyramid Pooling 예시

- 2x2 pyramid는 이미지를 몇개의 영역으로 나눌 것인지를 의미하고, bin는 나뉜 영역 하나의 크기를 의미한다.
- 32x32x256 크기의 이미지에 2x2 SPP를 적용하면 bin 하나는 16x16 크기이고, 16x16에서 max값을 뽑는다.
- 같은 방법으로 64x64x256 크기의 이미지에 2x2 SPP를 적용하면 bin 하나는 32x32 크기이고, 32x32에서 max값을 뽑는다.
- 둘 다 2x2 SPP를 적용하면 4x256(채널 수) 크기의 feature vector를 출력한다.
4. 한계점
1) 2000개의 region에 각각 CNN을 통과시킨다. → CNN 연산량이 너무 많아 속도가 느려진다.
2) 강제 warping → 큰 객체는 줄이고, 작은 객체는 늘려 정보 손실로 인해 성능이 하락할 수 있다.
3) CNN, SVM classifier, bounding box regressor를 따로 학습해야한다.
4) end-to-end 모델이라고 볼 수 없다.
기존에 R-CNN이 가진 한계점 중 1, 2번은 해결했지만, 아직 모든 한계를 해결하지는 못했다.