1. 기존 pre-training 방식

- LM(Language Modeling)
- 왼쪽에서 오른쪽으로 처리해 이전에 등장한 단어들을 기반으로 다음 단어를 예측
- GPT 등
- MLM(Masked Language Modeling)
- 랜덤하게 전체 토큰의 일부(일반적으로 15%)를 마스킹 처리한 후, 마스크 토큰의 원본 단어를 예측
- LM과 비교해 양방향 정보를 모두 고려하는 장점
- 전체 입력 토큰 중 15%만 학습하는 단점
- BERT, RoBERTa, XLNet 등
⇒ ELECTRA에서는 MLM pre-training 방식의 단점을 보완해 Replaced token detection 방식을 제안
- 단점 1: 전체 토큰의 15%만 학습해 학습 비용이 많이 듦
- 단점 2: [MASK]토큰이 pre-training 단계에서만 등장하고 fine-tuning 단계에서는 등장하지 않는 mismatch 문제
2. ELECTRA

- GAN 아이디어를 적용했기 때문에 electra 모델은 generator와 discriminator로 구성된다. GAN에서 generator는 더 잘 속이는 것을 목표로, discriminator는 속지 않기 위해 학습한다. GAN에서는 adversarial 학습을 하지만, ELECTRA는 log likelihood가 최대값이 되는 방향으로 학습한다.
- Generator는 마스킹 처리된 토큰의 원본 단어를 생성하고, discriminator는 입력으로 받은 토큰들이 원본 토큰과 동일한지 판별하는 역할을 한다.
조금 더 자세히 살펴보면,
- 단어 5개로 이루어진 입력 시퀀스가 들어오면 랜덤하게 일정 비율의 토큰을 [MASK]토큰을 바꾸어 마스킹 처리한다. 이 때 기존 BERT에서와 동일하게 전체 토큰의 15%를 마스킹한다. Generator는 [mask]토큰을 그럴듯한 토큰으로 변경한다.
- 이렇게 generator가 만든 토큰들을 discriminator는 입력으로 받아 각각의 토큰이 원본과 동일한지, 다른지 이진 분류를 수행한다. generator에 의한 생성여부가 아니라, 원본 토큰과 동일한지를 보기 때문에 real/fake가 아닌 originl/reaplced로 표기한다.
- discriminator가 모든 토큰에 대해 이진 분류를 수행하는 과정이 replaced token detection에 해당하며, 모든 토큰에 대해 문맥을 반영한 학습을 하기 때문에 MLM 학습방식보다 효율적이다.
2.1 Generator
⇒ BERT의 MLM과 동일한 역할
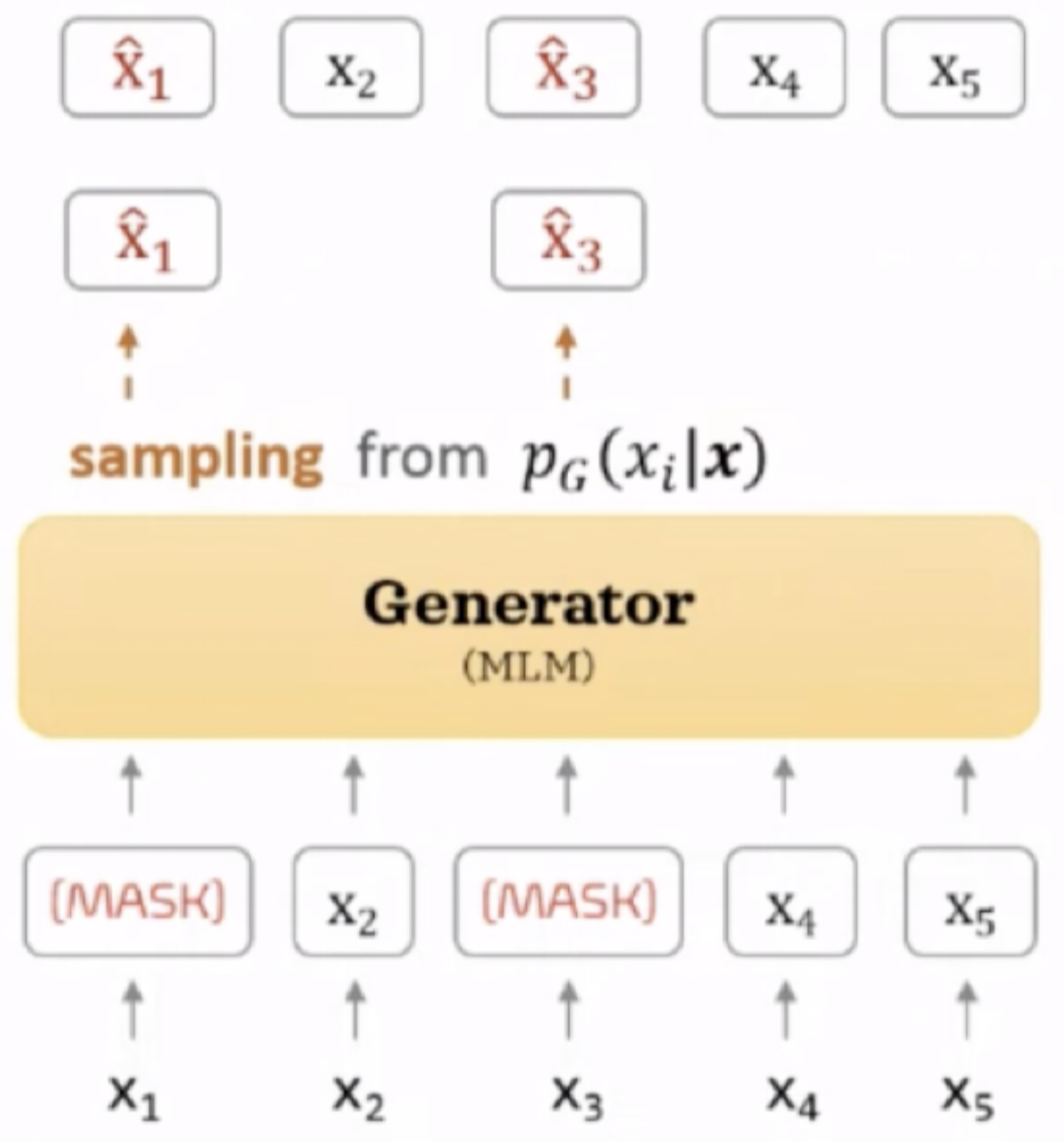
- 입력 시퀀스 $x = [x_1, x_2, … x_n]$ 에서 마스킹할 위치의 집합 $m = [m_1, m_2, … m_k]$ 를 결정한다.
- 마스킹할 토큰의 위치는 정수 1과 n 사이이다.균등 분포(uniform distribution)를 따르는 n개의 토큰 중 마스킹할 k개의 토큰 선택
- 입력 시퀀스에서 마스킹할 위치 k개를 선택한다. 랜덤하게 선택하기 때문에 균등분포를 따르는 $m_i$ 에서 선택한다.
- n: 입력 시퀀스의 토큰의 개수, 즉 입력 시퀀스의 길이
- k: 마스킹할 토큰의 개수, 보통 전체 토큰의 15%인 0.15n을 사용

2. 마스킹 하기로 결정한 토큰을 [MASK] 토큰으로 변경한다.
- $x^{masked} = REPLACE(x, m, [MASK])$
3. 마스킹된 입력 토큰 x^{masked} 에 대해서 generator는 원래 토큰이 무엇인지 예측한다.
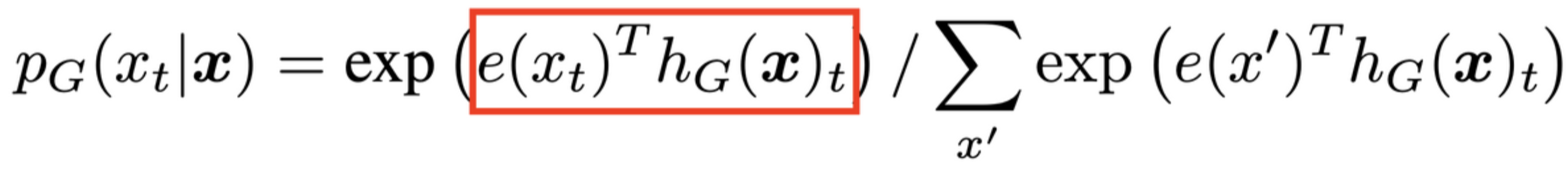
- Generator는 토큰을 입력으로 받아서 위의 $PG$와 같은 확률 분포를 생성(산출)한다.
- $e$ : token embedding
- 입력 시퀀스 x가 특정 위치(t)에서 $x_t$일 확률 = 빨간색 부분에 softmax를 취한 값
- $x$라는 입력 시퀀스가 주어졌을 때, 특정 위치 t에 토큰 $x_t$가 들어갈 확률은 토큰 임베딩 $e(x_t)^T$과 generator의 hidden layer를 거친 $h_G(x)_t$에 softmax를 취한 값이다.
2.2 Discriminator
⇒ 각 토큰이 original인지 replaced인지 이진 분류로 학습
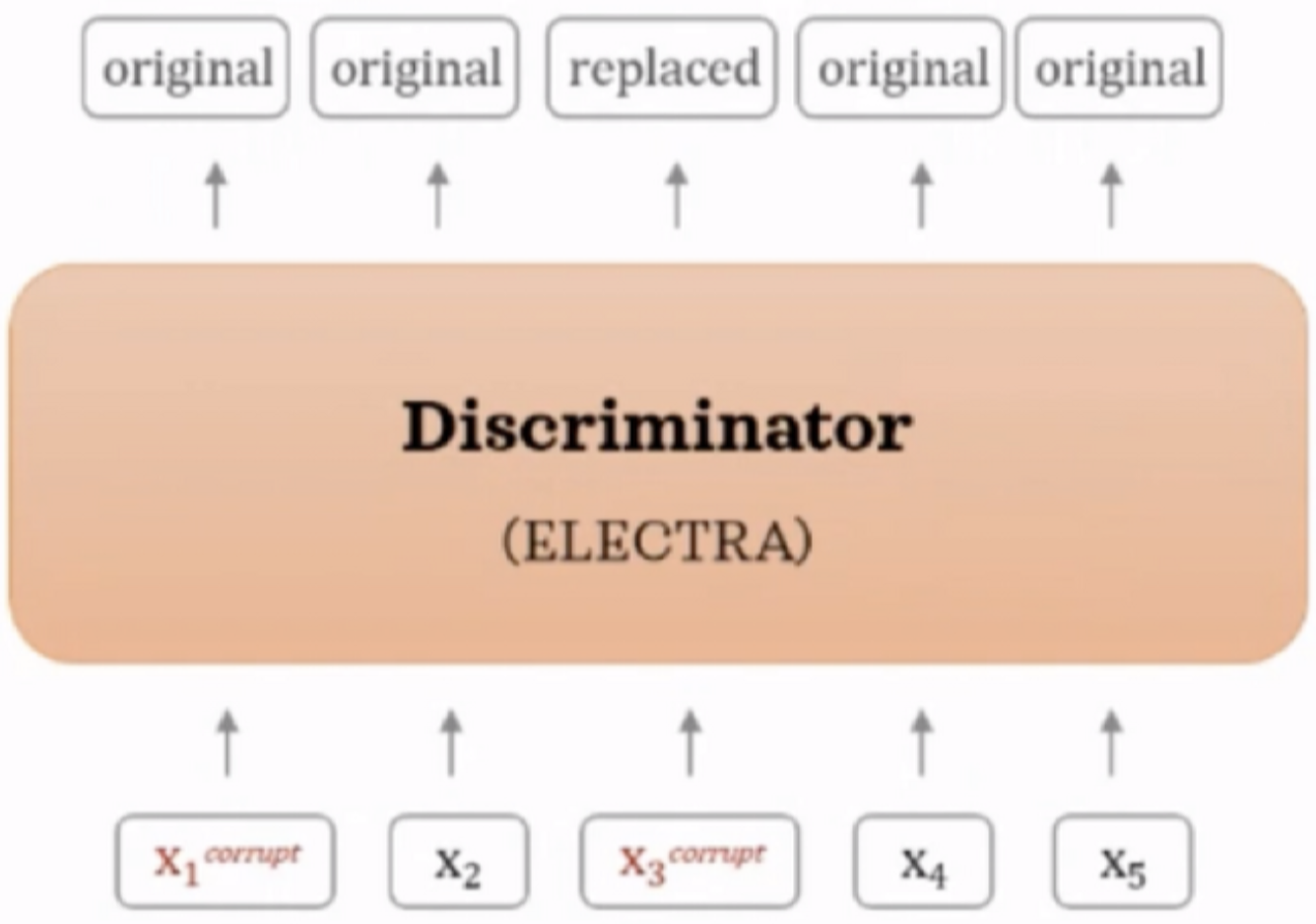
1. Generator G를 사용해 마스킹된 입력 토큰을 예측한다. (Generator의 1-3단계)
2. G에서 마스킹할 위치 m에 해당하는 토큰을 [MASK]가 아닌 G의 softmax 분포 $PG(x_t|x)$ 에 대해 샘플링한 토큰으로 치환(corrupt)한다.
예를 들어:
- 원본 입력 = [the, chef, cooked, the, meal]
- generator의 입력 = [[MASK], chef, [MASK], the, meal]
- discriminator의 입력 = [the, chef, ate, the, meal]
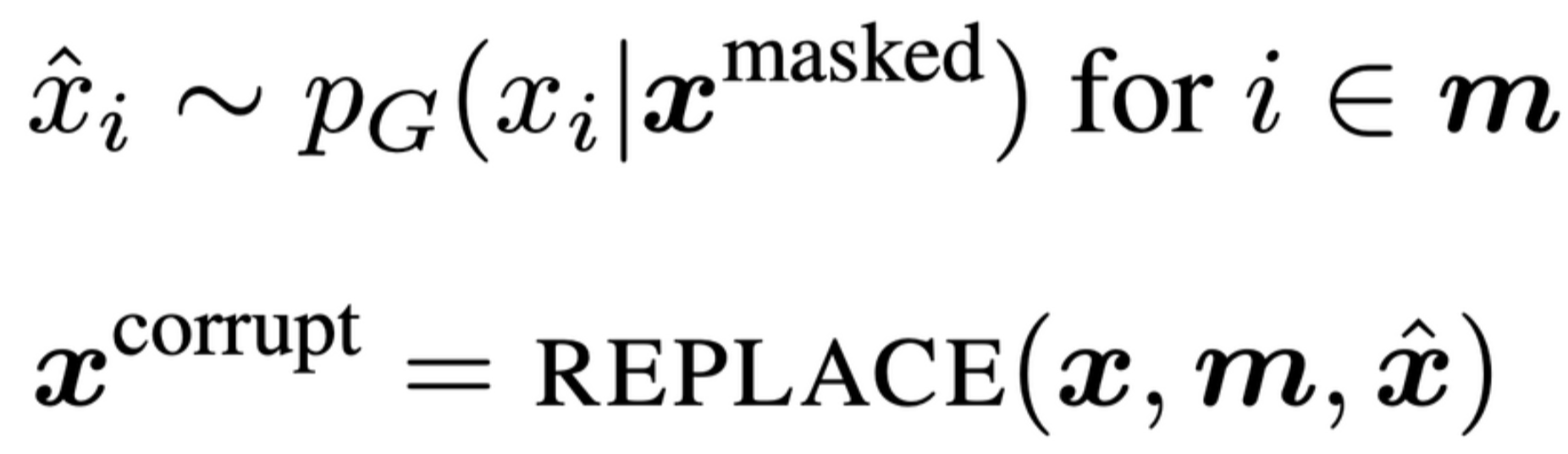
3. Generator가 생성한(치환한) 입력 x^{corrupt} 에 대해 discriminator는 각 토큰이 원래 입력과 동일한지(original), 치환된 것인지(replaced) 예측한다.

3. Loss function

최종적으로 ELECTRA 모델은 generator의 MLM loss와 discriminator의 loss를 결합한 값을 최소화하는 방향으로 학습한다. 이를 본 논문에서는 joint training이라고 표현했으며, generator와 discriminator를 순차적으로 학습하지 않고, generator와 discriminator가 함께 학습되는 것을 의미한다. 이진 분류이기 때문에 sigmoid 활성화 함수를 사용했다.
3.1 Generator loss
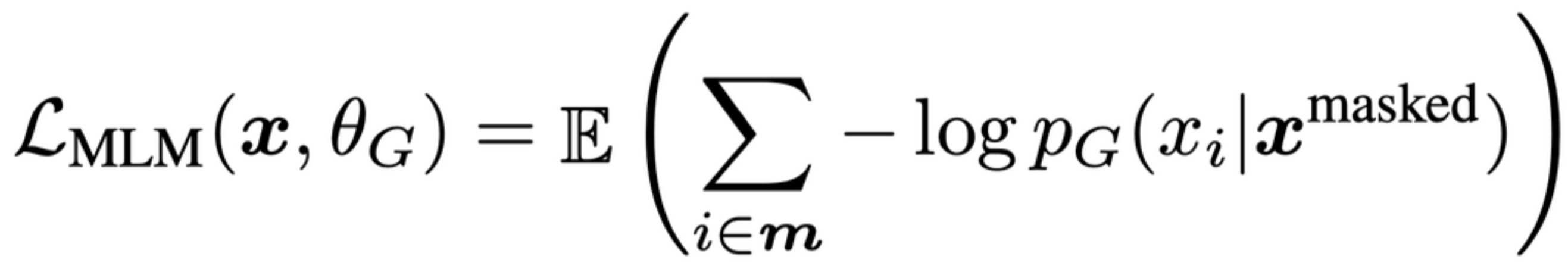
$PG(x^i | x^{masked})$ 에 대하여 maximum log likelihood를 사용해 학습한다. Generator의 likelihood가 최대가 되는 분포를 찾는 식이다. E는 expected value operator로, 수식의 평균 기댓값을 의미한다. (참고)
3.2 Discriminator loss
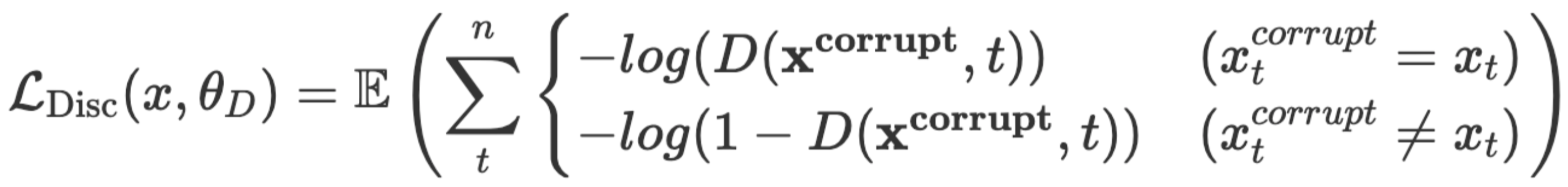
Discriminator는 이진분류이기 때문에 cross entropy loss를 사용한다.
왜 generator는 pre-training 단계에서만 사용하고, fine-tuning에서는 사용하지 않을까?
⇒ generator는 단순히 [MASK]토큰을 그럴듯한 단어로 생성하는 역할이다. 입력 sequence의 모든 토큰의 앞뒤 문맥을 파악하며 학습하는 것은 discriminator가 담당하기 때문에 fine-tuning 단계에서는 discriminator만 사용한다. BERT에서 MLM학습이 pre-training 단계에세만 이루어지고, fine-tuning 단계에서 이루어지지 않는 것과 비슷한 맥락이라고 볼 수 있다.
4. Experiments
4.1 성능 평가
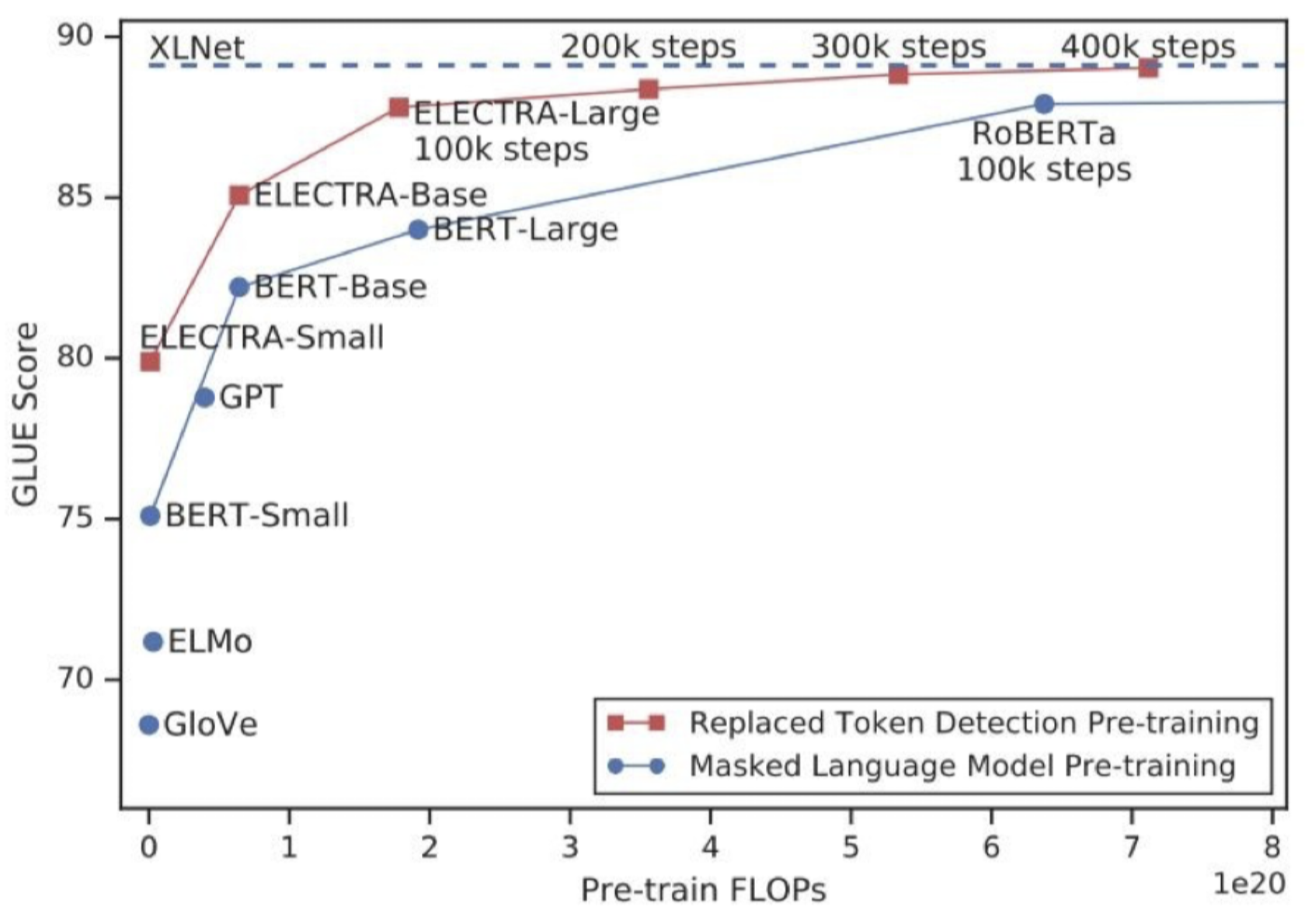
- 그래프에서 파란색이 MLM, 빨간색이 ELECTRA를 의미한다.
- 자연어 벤치마크 데이터셋인 GLUE 점수도 더 높다.
- FLOPs는 FLoating point OPerationS의 약자로, 부동 소수점 연산이 얼마나 수행되는가? 즉, 모델의 연산량이 얼마나 많은지 나타내는 metric이다. 비슷한 FLOPs일 때, RoBERTa는 100k까지 학습하고, ELECTRA-large는 400k까지 학습이 진행된걸 확인할 수 있다.
4.2 Weight Sharing
몇몇 논문에서 가중치 공유(weight sharing)를 통해 성능 향상을 보여주었다. ELECTRA에서도 generator와 discriminator간의 가중치를 공유해 성능을 높히고자 했다. 3가지 가중치 공유 방법을 실험했다.
- No weight sharing: 83.6
- Embedding weight sharing: 84.3
- All weight sharing: 84.4 (generator와 discriminator 크기가 동일해야 가능)
⇒ 모든 가중치를 공유하는 방법이 성능이 가장 높지만, 두 네트워크의 크기가 같아야 하기 때문에 연산량이 많다. 반면에 임베딩 가중치만 공유한 경우에도 성능이 유사하게 높기 때문에 논문에서는 임베딩 가중치만 공유하는 방법을 사용했다.
4.3 Smaller Generators
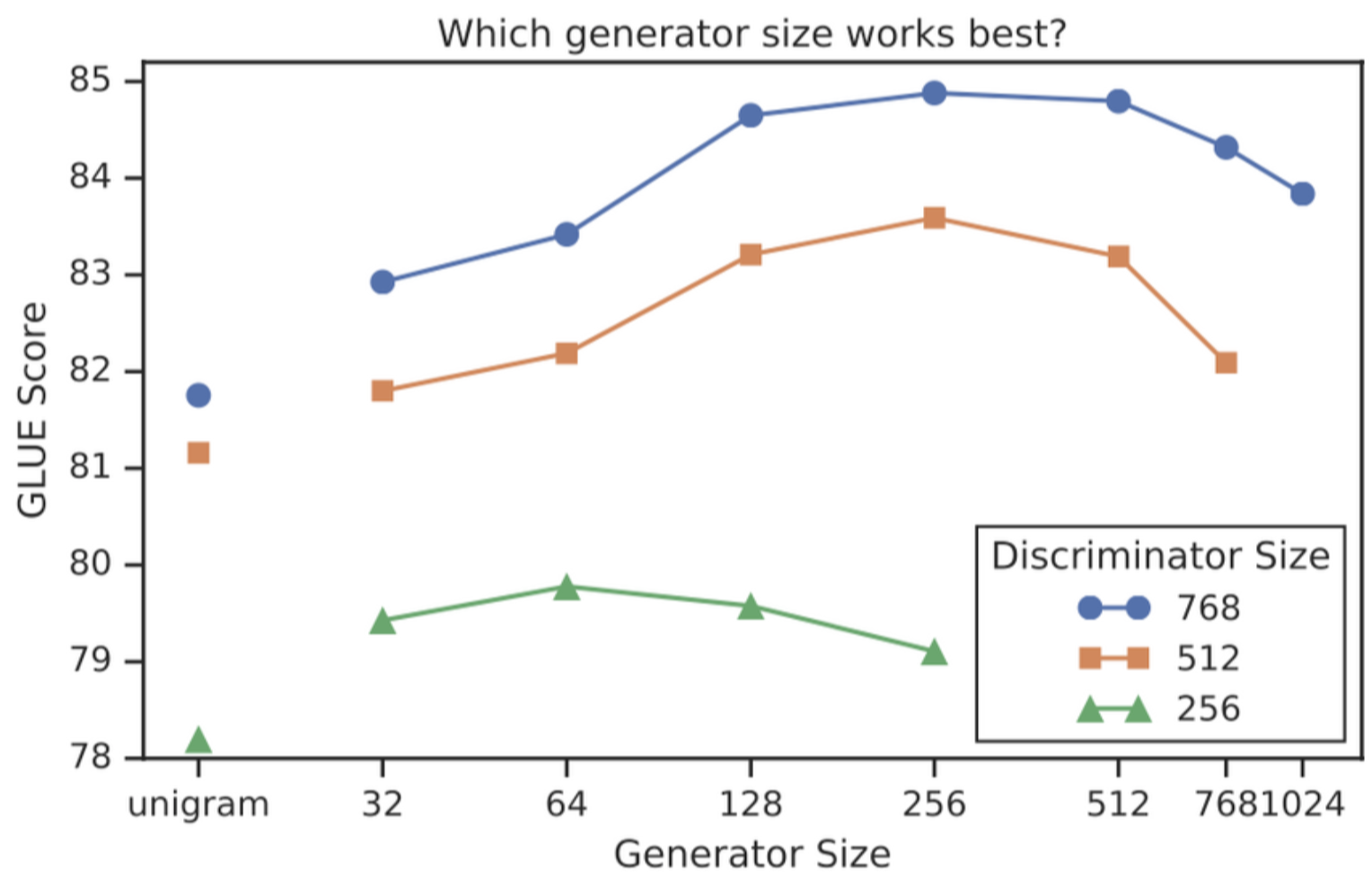
- generator와 discriminator의 크기가 동일하다면 기존 MLM(BERT) 방식보다 연산량이 2배가 필요하다. generator의 크기를 줄여 연산량을 줄이기 위해 두 네크워크의 크기에 따른 성능 실험을 진행했다.
- generator의 크기가 클수록 성능이 높지 않고, discriminator 크기의 1/4 ~ 절반일 때 성능이 가장 높다. generator가 단어를 너무 잘 생성하면 discriminator 입장에서는 분류 난이도가 상승하기 때문에 generator의 크기가 크면 성능이 떨어진다고 추측할 수 있다.
4.4 Training Algorithms
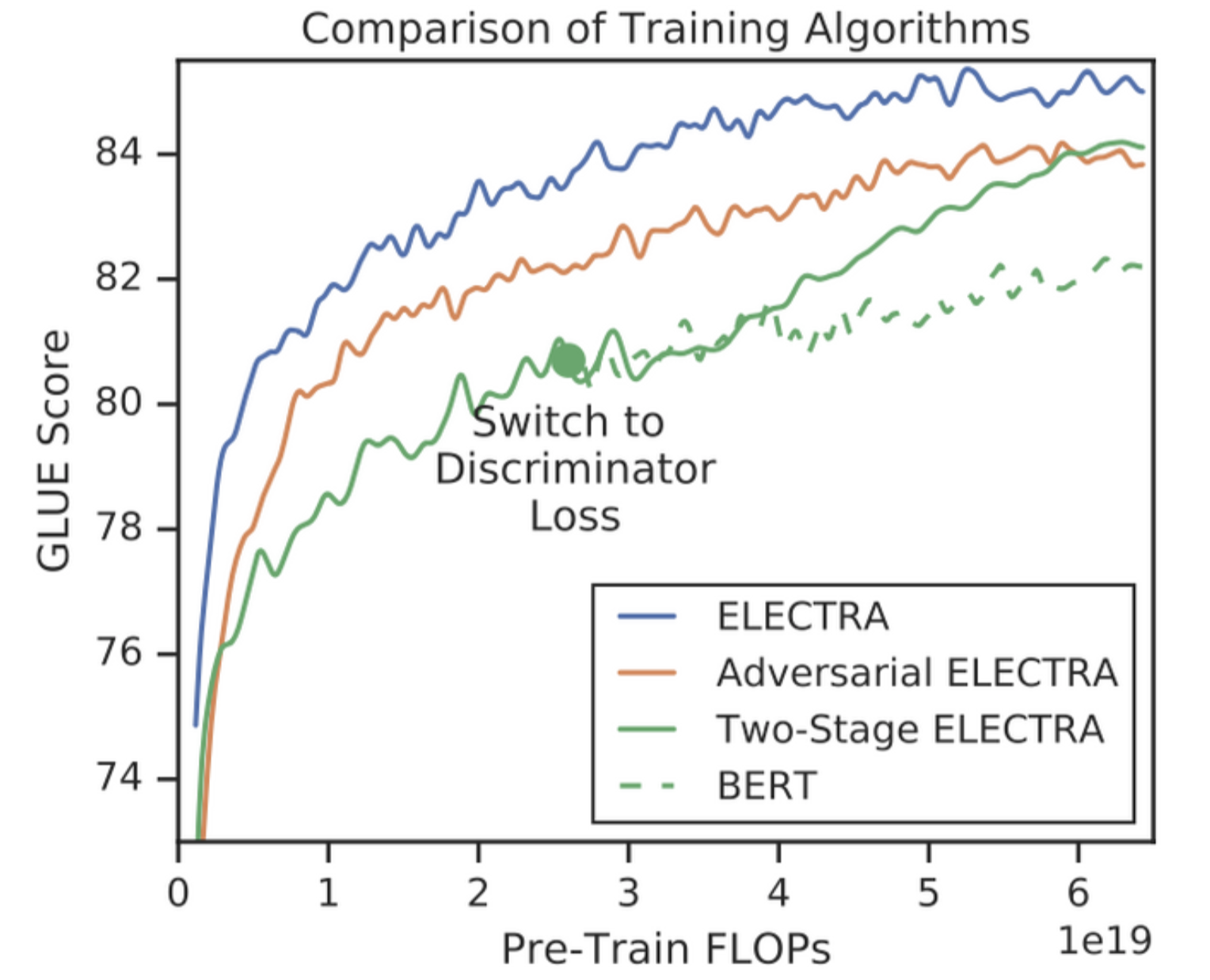

- Joint training: generator loss와 discriminator loss를 합쳐 두 네트워크를 같이 학습 (위의 수식)
- Adversarial training: GAN처럼 두 네트워크가 적대적으로 학습
- Two-stage training: generator 학습 이후 disciminator를 학습하는 방법 (generator의 weight로 disciminator를 초기화)
- 먼저 학습된 generator가 생성한 단어를 discriminator가 예측하기에는 어려워 one-stage보다 성능이 좋지 않다.
4.5 Small Models
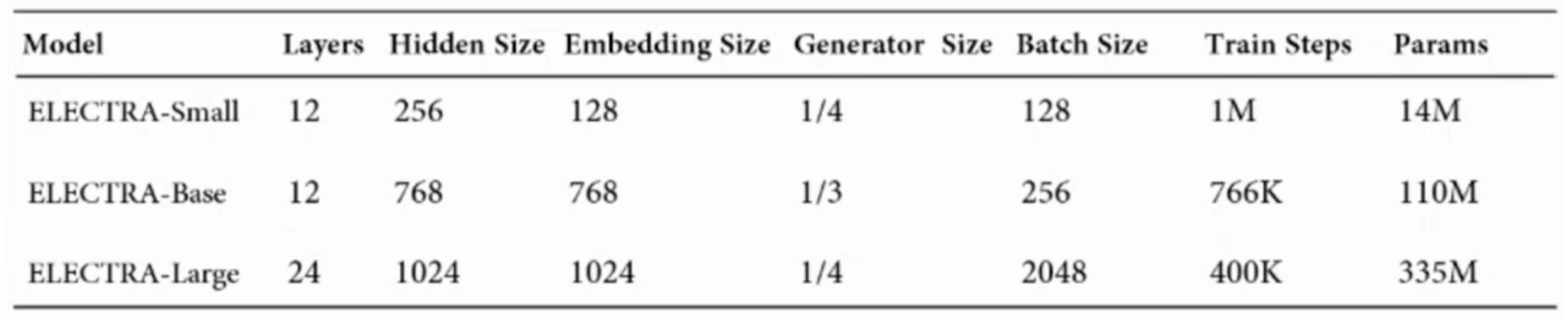
pre-training의 효율성 향상이 ELECTRA의 목표였기 때문에 빠르게 학습이 가능한 ELECTRA-small 모델과 BERT의 성능을 비교했다.
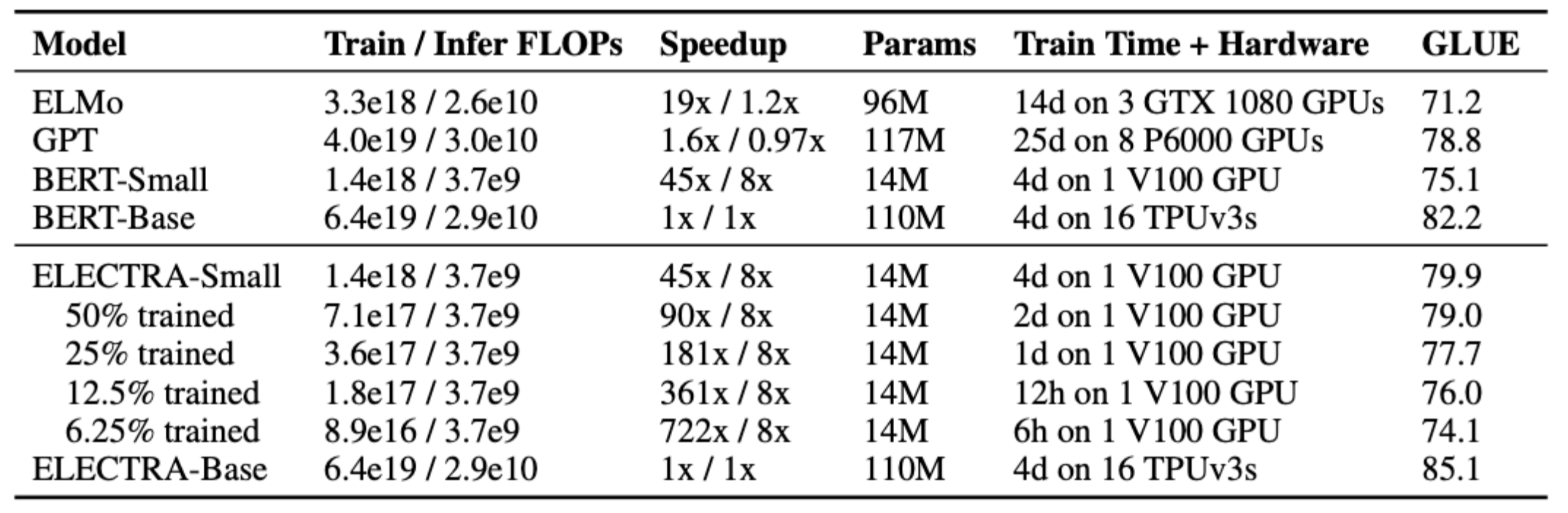
- ELECTRA-small은 연산량은 적지만 더 큰 모델보다 높은 성능을 보임
- ELECTRA-base는 BERT와 비교하기 위해 BERT와 크기가 동일한 모델
4.6 Large Models
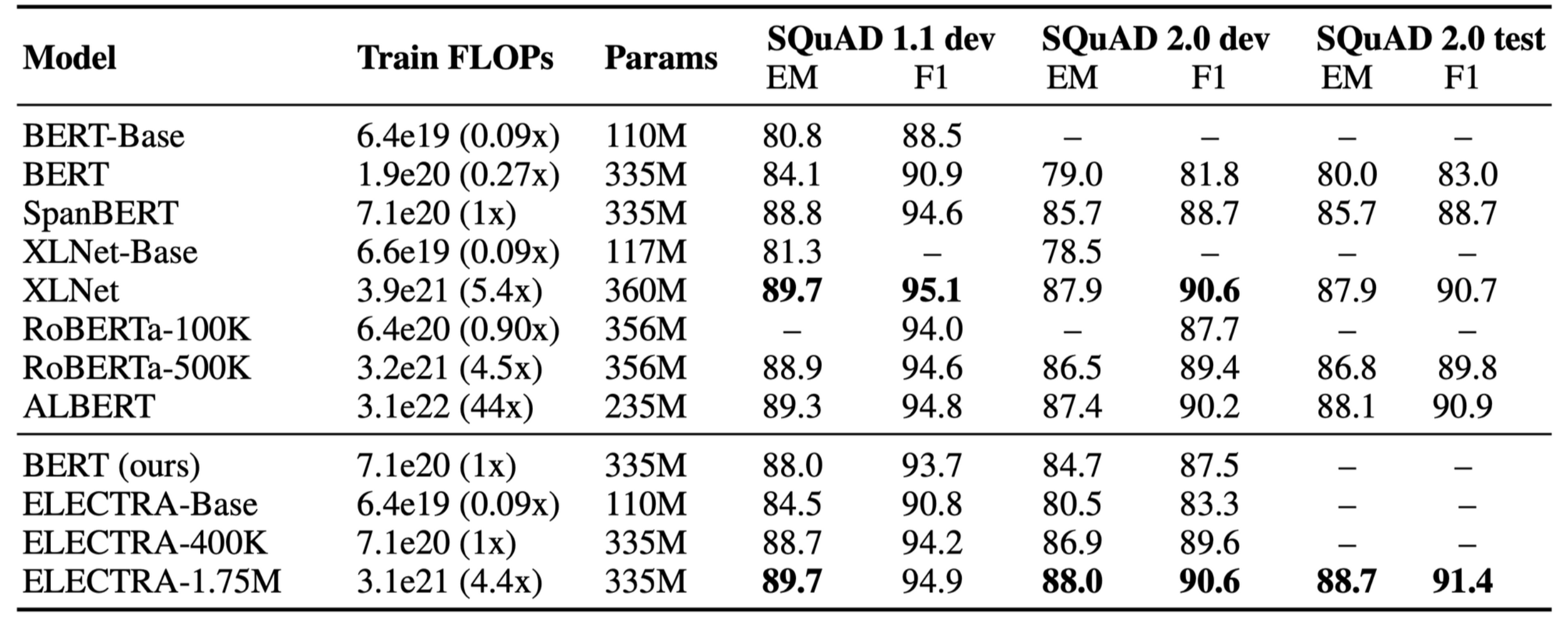
- replaced token detection pre-training 방식이 큰 모델에서도 잘 작동하는지 확인하기 위한 실험을 진행함
- ELECTRA-1.75M 은 대부분의 downstream task에서 높은 성능을 보임
- SQuAD 2.0 데이터셋에서 성능 차이가 컸는데, 저자들은 이를 discriminator를 학습하는 과정에서 얻은 장점이라고 추측함
4.7 Efficiency Analysis
"기존 MLM pre-training은 [MASK] 토큰을 사용해 일부 토큰에 대해서만 예측을 수행해 비효율적이다.” 라는 가정을 했다. 어떤 점에서 ELECTRA가 어떤 점에서 BERT보다 더 좋은 성능을 보이는지 알아보기 위해 실험을 진행했다.
- Full ELECTRA: 논문에서 소개한 모델
- ELECTRA 15%: discriminator의 loss 중 (generator에서) 마스킹 처리한 토큰에 대한 loss만 사용
- Replace MLM: [MASK]토큰 대신에 랜덤하게 다른 토큰을 사용. pre-training 단계에서 [MASK] 토큰을 사용하지 않으면 성능이 오를까? ⇒ [MASK] 토큰을 사용하지 않는다고 해서 성능이 올라가지 않는다.
- All-tokens MLM: generator가 마스킹 처리된 토큰뿐만 아니라, 입력 토큰을 모두 생성

모두 토큰을 예측하는 방식이 성능 향상에 가장 큰 영향을 미치는 것을 알 수 있다.
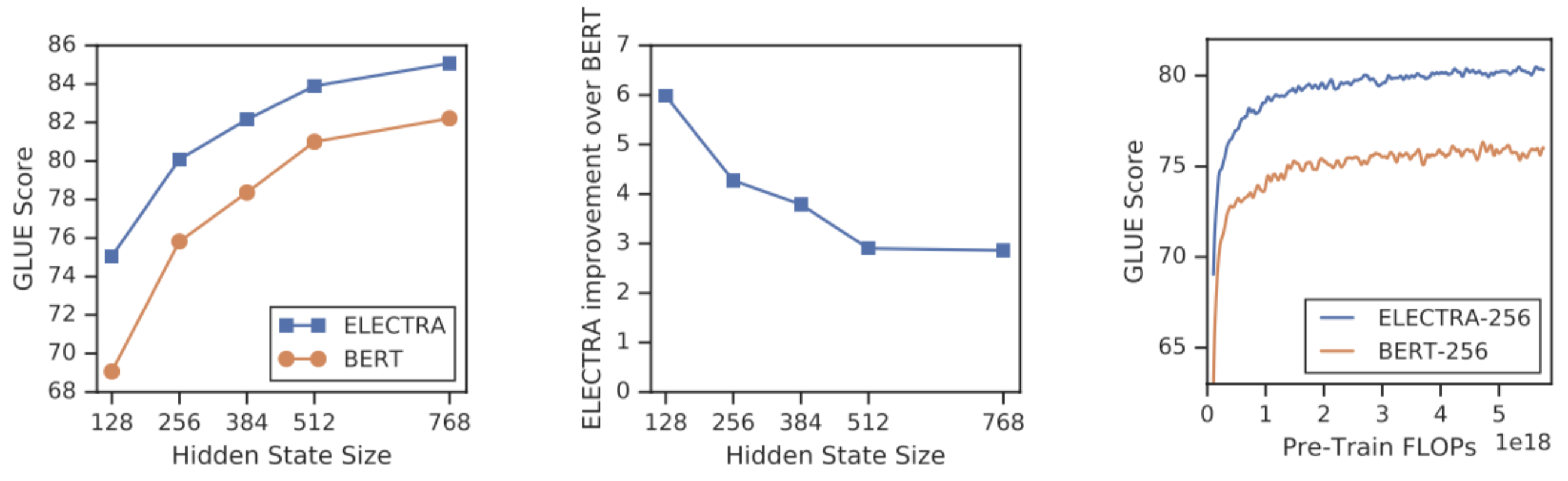
가장 왼쪽 이미지를 보면 모델이 작을수록, 연산량이 적을수록 BERT와 ELECTRA의 성능 차이가 큰 것을 확인할 수 있다.
참고한 자료들
'Deep Learning > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] VGGNet (CVPR 2014) (0) | 2022.07.24 |
|---|